This forum is disabled, please visit https://forum.opencv.org
| 2019-02-03 22:38:38 -0600 | received badge | ● Popular Question (source) |
| 2018-11-24 00:40:44 -0600 | received badge | ● Popular Question (source) |
| 2018-10-12 23:08:37 -0600 | received badge | ● Notable Question (source) |
| 2018-08-14 10:16:25 -0600 | received badge | ● Nice Question (source) |
| 2018-03-15 06:48:19 -0600 | marked best answer | How to perform Linear Discriminant Analysis with OpenCV Final Update: Based on the help berak gave me, I've written a new question including all the code that he has helped me with in one place, but also with the aim to calculate the probability when classifying instead of finding the nearest datapoint. I recently tested out scikit-learn's LDA with some different images and could see clear clusters form. Now I want to translate that code into C++ for my main program I was wondering if anyone had any knowledge/experience working with the OpenCV library doing things like Eigenfaces or Fisherfaces. I'm particularly interested in whether I can use LDA directly without having to use one of the pre-written facial recognition libraries. Update Thank-you berak for your amazing help and great examples in the answer. I hope it would be ok if I double checked a few things that I'm a little confused about? So if I have my training data set up like this: Then I initialise the LDA: Next, I need to get the mean, eigenvectors and projections like you suggested. In your comment above you stated how lda.compute computes the eigenvectors, so does this mean I can retrieve the eigenvectors with this command? I'm still a little confused as to how I retrieve the mean and also where does feature_row in this code come from? Once I now have the Mat Projected matrix, the mean and eigenvectors, I then use this bit of your code to get the features Matrix Now I have this training done, can I use the function you wrote below to pass a new 1D tag matrix (that's what Mat feature is right?) and predict what type it is? So the final step is for me to take the new tag (feature) and then to iterate through each row of the features matrix I created during the training step, and find the item with the shortest distance and return it's label. Will the data be in x, y coordinate format or is there another way I should try to find the shortest distance? Update 2 Thanks so much for the clarification, I think I understand, is this correct? Then when I want to predict I take my ... (more) |
| 2018-03-05 08:17:03 -0600 | received badge | ● Popular Question (source) |
| 2017-08-07 09:54:32 -0600 | received badge | ● Popular Question (source) |
| 2017-07-10 14:06:51 -0600 | received badge | ● Notable Question (source) |
| 2017-03-02 21:05:13 -0600 | received badge | ● Popular Question (source) |
| 2016-12-10 13:33:06 -0600 | received badge | ● Popular Question (source) |
| 2016-02-03 08:25:51 -0600 | received badge | ● Nice Question (source) |
| 2016-01-10 17:57:34 -0600 | asked a question | If I want OpenCV to use all the cores in my computer, do I have to compile it myself or can I do this with apt-get? I've been using OpenCV on the Raspberry Pi 2 (4 cores). I installed it with apt-get, yet whenever I use OpenCV via Python it only ever uses 25% of my CPU potential (1 core). Is there a way to install OpenCV via apt-get that allows me to utilise threading in the library methods or will I have to compile it myself as apt-get is unable to do this? I get the impression that this isn't occurring because even when I call OpenCV methods like haar cascade, the CPU load never goes beyond utilising a single core. I understand that Python has the GIL, but I'm I'm I'm curious about whether the methods that I'm calling from OpenCV will be utilising all 4 cores of my machine, even if I haven't compiled it myself with the multithreading flag (as I've installed it with apt-get). |
| 2016-01-10 17:53:08 -0600 | commented question | Background averaging not working Unfortunately not, I ended up going to see some researchers in the engineering department at my uni and they pretty much agreed that you're going to have to train a ML algorithm to distinguish bee from background in order to extract the background, assuming parts of the background are visible at all at some point. |
| 2015-11-13 11:18:06 -0600 | commented question | Background averaging not working Thanks! I'll give it a read :) |
| 2015-11-13 08:18:52 -0600 | commented question | Background averaging not working Sure: https://www.youtube.com/watch?v=VWbX7... That said, this was an example with fewer bees where simple averaging works perfectly. I can look into uploading the trickier videos tho if you were interested. |
| 2015-11-13 06:29:37 -0600 | asked a question | Background averaging not working I'm working on a problem where I'm trying to use background averaging to see what the frame looks like in a beehive behind the bees. I've been trying to use standard averaging (I take an image every 1 or 4 seconds over the course of my 3 hour video) as well as other techniques like mog and mog2. The problem is that there is an extremely high density of bees in the centre that is tightly packed and barely moving, so while I end up with a great view of the background around the middle, the centre turns into a bit of a smear like this:
Does anyone have any advice on what I could do to improve things? I spoke to a researcher who suggested something called "sparse coding" as one possible options and I'm curious if OpenCV has anything like that or if anyone knows of any other techniques I could try. |
| 2015-11-13 06:22:03 -0600 | commented answer | Homebrew installation of OpenCV 3.0 not linking to Python 3 Yes, the problem is that home-brew doesn't link the .so file to the Python path. |
| 2015-09-09 07:12:03 -0600 | asked a question | OpenCV cannot read MP4 videos I'm using OpenCV 2.4.8 on Ubuntu 14.04 to read in some MP4 videos. The program works on Macs and other Linux machines, but for some reason when I compile and run the program it gives me these errors before exiting: |
| 2015-09-06 04:09:38 -0600 | asked a question | Homebrew installation of OpenCV 3.0 not linking to Python 3 When I install OpenCV 3.0 with Homebrew, it gives me the following directions to link it to Python 2.7:
While I can find the python2.7 site packages in opencv3, no python34 site packages were generated. Does anyone know how I can link my OpenCV 3.0 install to Python 3? |
| 2015-08-25 08:28:49 -0600 | asked a question | Converting OpenCV grayscale Mat to Caffe blob I've been following an example I was referred to on how to convert an OpenCV Mat into a Caffe object I could make predictions from. From what I understand, the first section scales the image and then initialises the caffe class "TransformationParameter": Then, the OpenCV Mat "patch" is converted into "input_blob". I've changed this part because I've loaded in my image in grayscale instead of colour. Finally, I'm not too sure what this section does - if I already have my OpenCV Mat converted to a Caffe blob, why do I need to push back on the "input" vector and pass it to the net? Can't I pass input_blob directly into the net to get my prediction back? |
| 2015-08-25 08:08:37 -0600 | commented answer | Classifying OpenCV Mat objects with Caffe |
| 2015-08-25 08:08:33 -0600 | commented answer | Classifying OpenCV Mat objects with Caffe Thanks a lot! I also found another example of how someone had managed to convert OpenCV Mats into Caffe blobs but I'm struggling a little to understand it, any chance you could take a look? |
| 2015-08-23 08:09:34 -0600 | asked a question | Classifying OpenCV Mat objects with Caffe Once I have trained my Caffe model (and have the pretrained.caffemodel file), how do I integrate this into a C++ program to make predictions? I'm using OpenCV to extract grayscale images (Mat datatype) and am trying to determine how I can get the Mat into a format that Caffe can work with. |
| 2015-08-17 03:29:40 -0600 | asked a question | Image descriptors to train SVM on I've been processing some tags (circles, rectangles and blank) using a median blur, Gabor filters and increasing the contrast. The result, which seems to remedy most of the variation in lighting, looks like this:
Does anyone know of some reliable descriptors (such as shape) that I could extract from images like this to feed into an SVM in order to identify the type of tag? I've tried feeding HOG, LDA, PCA and the raw pixels into an SVM without success (accuracy in the 40% range). |
| 2015-08-10 09:52:46 -0600 | commented question | Ideas for separating LDA clusters to improve SVM accuracy? I've tried using an SVC with RBF kernel but that didn't seem to work any better unfortunately. |
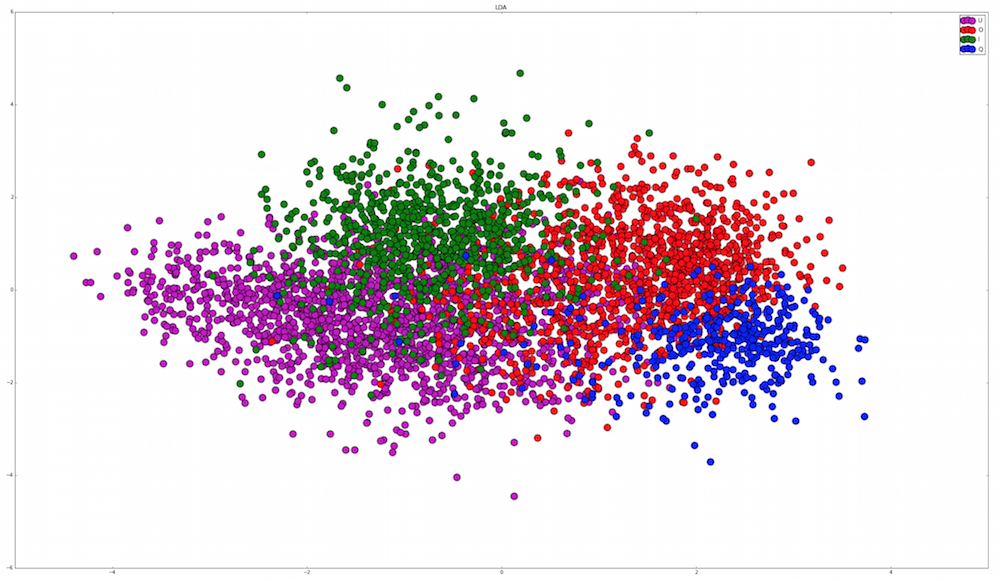
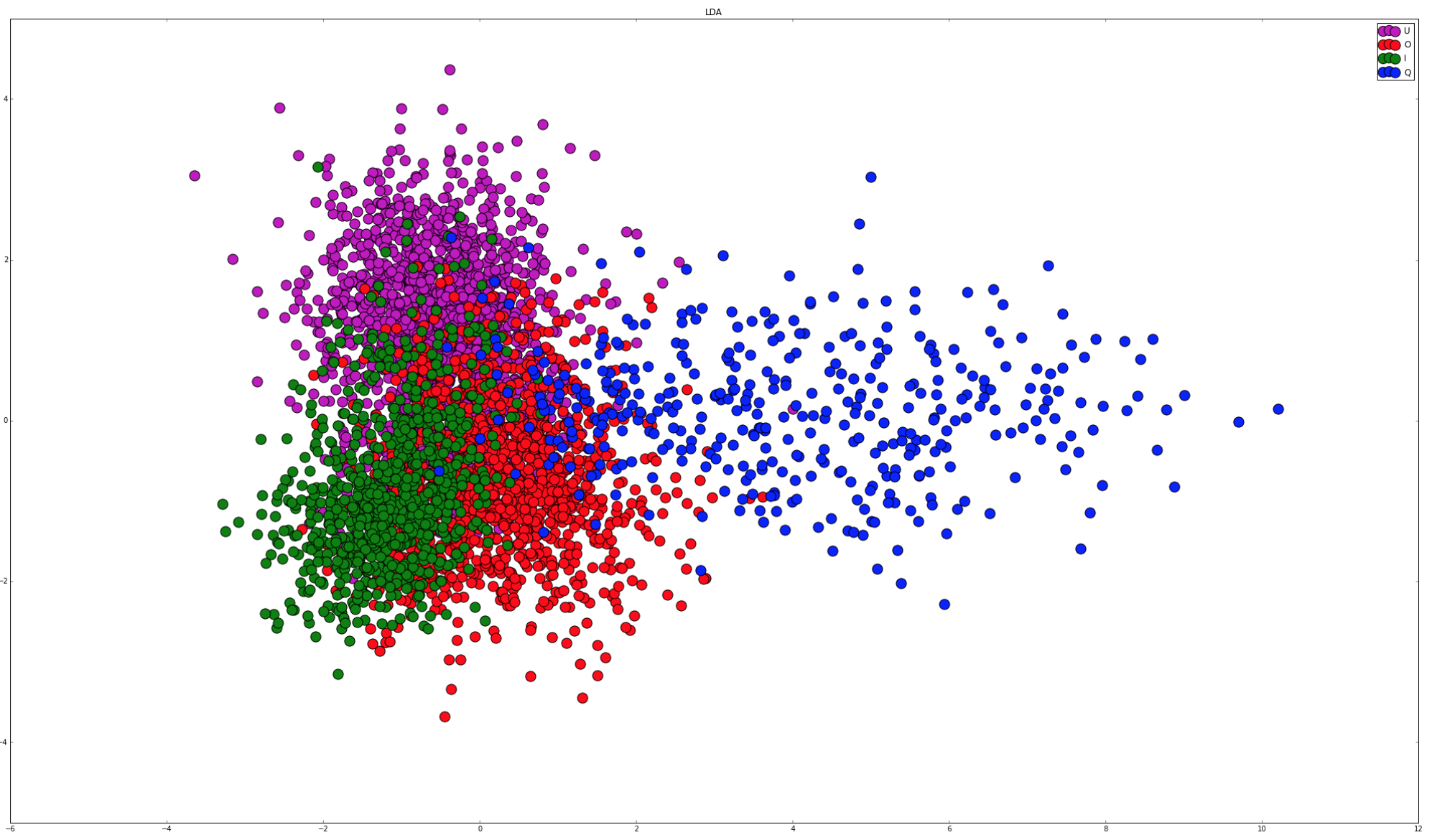
| 2015-08-10 00:30:33 -0600 | asked a question | Ideas for separating LDA clusters to improve SVM accuracy? I've been trying to classify some tags (each tag is a 24*24 pixel image) that I have on the backs of insects. There are 3 tag types: circle (O), rectangle (I) and Queen (Q). There's also a fourth tag type: unknown (U) because sometimes the angle that the tags are extracted at or the lighting mean that it isn't possible to tell what type of tag it is. There's quite a bit of variation in lighting and tag quality too, which you can see in the image below (image 7.png is actually a rectangle that's a little bit blurry although in the image I said it was unknown):
I've tried to use PCA and LDA on this data, LDA initially looked promising when I only trained it with easily lit tags, however once I include all tag types, the LDA looks a little less clear:
If I apply histogram equalisation to the tags, the queen tag seems to separate out reasonably well, and if I train an SVM with two classes (queen vs all others) it's 95% accurate.
I could train two SVMs where the first extracts the queen and then I use the other one to separate out the circles and rectangles. The problem is that there seems to be a fair bit of overlap between the LDA distributions of these shapes. Does anyone have any advice on other image processing, dimensionality reduction or machine learning techniques that I could try to separate these two groups? |
| 2015-08-04 08:12:31 -0600 | commented question | Does the one class SVM ignore training labels automatically? Sure, something like this. |
| 2015-08-03 18:49:19 -0600 | commented question | Does the one class SVM ignore training labels automatically? I was reading some articles where they were saying that a one class SVM was useful if you weren't just trying to separate out two things but had the things you wanted to identify plus everything else. If I use a one class SVM and then feed it new data what will be the result if I give it an inlier vs an outlier? |
| 2015-08-03 02:04:52 -0600 | asked a question | Does the one class SVM ignore training labels automatically? If I'm using CVSVM::ONE_CLASS, will the program just ignore the Mat containing my training labels? I have different classes in my data but there's also outliers which I cannot classify and I'd like my first SVM just try to determine if I can classify they data or if it's an outlier. Does this sound like the kind of thing a one class SVM is good for? I was also wondering will the SVM will return 1 (is a class it recognises) or 0 (is an outlier) or will it return other values? |
| 2015-08-02 19:25:40 -0600 | asked a question | Can I train a one class SVM with OpenCV? I was reading an interesting article called 'Detecting Anomalies' and it mentioned how you can use a one-class SVM to try detect anomalies in your data. Does OpenCV's SVM support the ability to train a one class SVM (rather than having a minimum of two classes)? |
| 2015-07-14 18:16:21 -0600 | commented question | Adding "ambiguous" class to SVM I'll give it a go :) thanks for the advice |
| 2015-07-13 23:55:10 -0600 | commented question | Adding "ambiguous" class to SVM So if I had 3 classes, I should train 3 SVMs, and then look at the ones that classifies the tag in a 'known' category than see how confident it is? |
| 2015-07-13 21:26:11 -0600 | asked a question | Adding "ambiguous" class to SVM I've trained an SVM to classify images of tags my program can extract, however I used data where I could tell which tag type was which myself visually. Unfortunately, for maybe half the tag images I can't tell which type it belongs to (and thus didn't include it in my training set), and as a result the SVM classifies perfectly on my training data (when I split a training set from it), but with the real data it's wrong about half the time. Would the best option here be to include an "ambiguous" class of data to my SVM with several hundred/thousand images of the tags where I can't tell what type it is? I'd rather have more instances of "unknown" classifications and be right more often when I do try to make a prediction. |
| 2015-07-13 21:17:34 -0600 | commented question | SVM Confidence with 3 Classes Thanks for the advice guys, do you think a possible solution could be to add an additional class to my SVM containing "ambiguous" data? |
| 2015-07-12 21:24:38 -0600 | asked a question | SVM Confidence with 3 Classes I really need to access the confidence of the prediction my SVM has made, and the method gives me the option of "returnDFVal":
Unfortunately, I have 3 classes, so this doesn't work for me. Is there any way I can get around this or another method I can call to determine the confidence of my prediction? |
| 2015-07-06 19:57:45 -0600 | commented question | LDA loaded does not work Apologies, I mixed myself up with variable names when I wrote the example and the variables in my code. I've pasted the main section of code into the question now, where I'm still getting that error even though my matrix is the right size. |
| 2015-07-06 08:11:52 -0600 | asked a question | OpenCV 3.0 not longer recognises 'CvSVM' I recently updated to OpenCV 3.0, and my old code which trained an SVM has stopped working. Now writing this gives me the following error:
Does anyone know whether they've changed the names in OpenCV 3.0 or if it's a bug in the new release? |
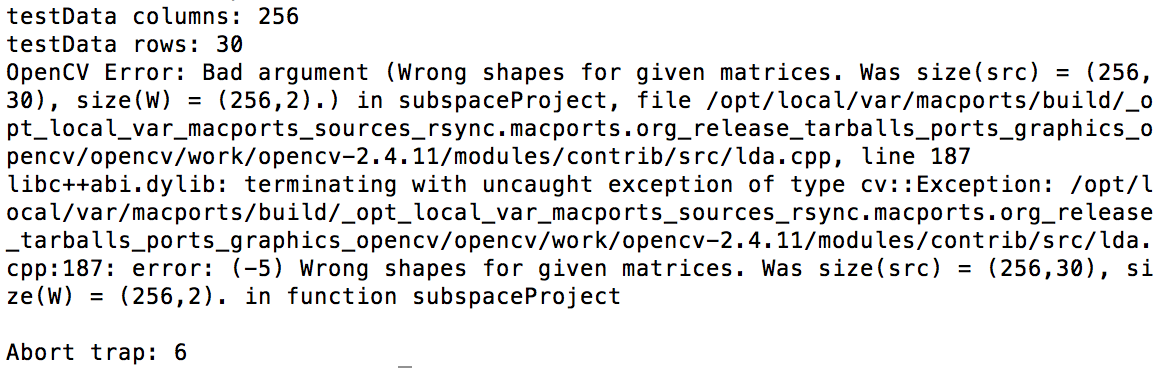
| 2015-07-06 07:03:06 -0600 | commented question | LDA loaded does not work Do you happen to know what the error "Was size(src) = (256,30), size(W) = (256,2). in function subspaceProject" means? |
| 2015-07-06 06:56:20 -0600 | commented question | LDA loaded does not work But thank-you for the suggestion, it's something I should have been more explicit about and would have made a lot of sense given the error messages, which is why I'm finding this so confusing! |
| 2015-07-06 06:55:02 -0600 | edited question | LDA loaded does not work I've trained my LDA on several thousand images and was keen to save it so that I could load it in the main program that would be doing predictions (rather than running it fresh each time). I knew that with an SVM I can use a command like this to save it: So I tried a similar thing for LDA, and that also seemed to work: Then, in my prediction program, I load the LDA and try to project the new data: The loading part worked fine, however when I try to project the new data, I get this error: But that doesn't make sense to me: the data I trained the LDA on had 256 columns, it was grayscale pixel values. I did exactly the same processing for my test images as I did for my training images. If I don't bother about loading the LDA and just have the prediction stage in the same program it works perfectly (same code for processing the test images too!), so I can't understand why this error keeps occurring. To clarify, I've been running std::cout on trainData and to confirm it has 256 cols and 30 rows but still get the error. This is driving me crazy because if I deliberately make testData an incorrectly sized matrix (not the 256 cols it's expecting) than I get the same answer!
The main section of code |