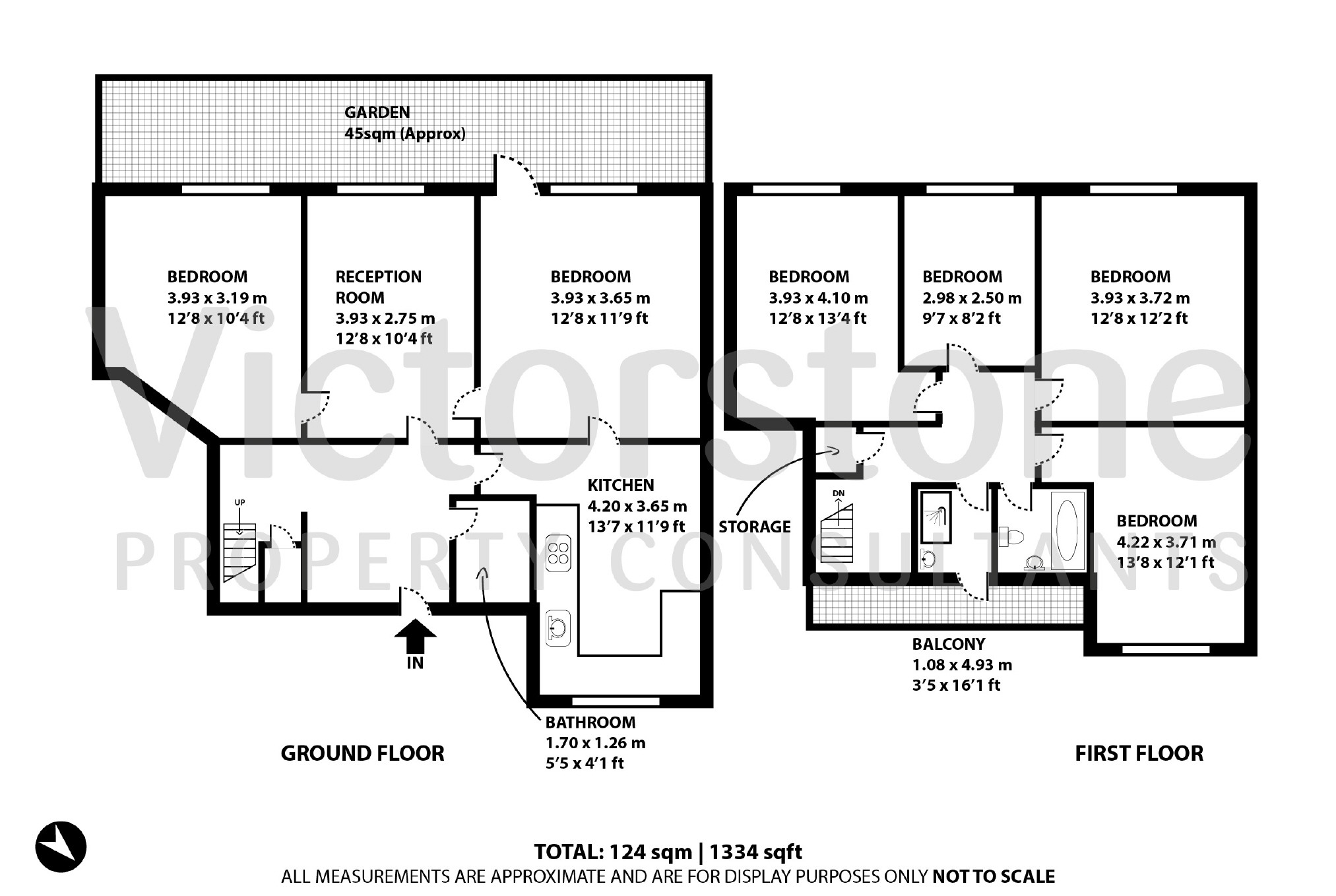
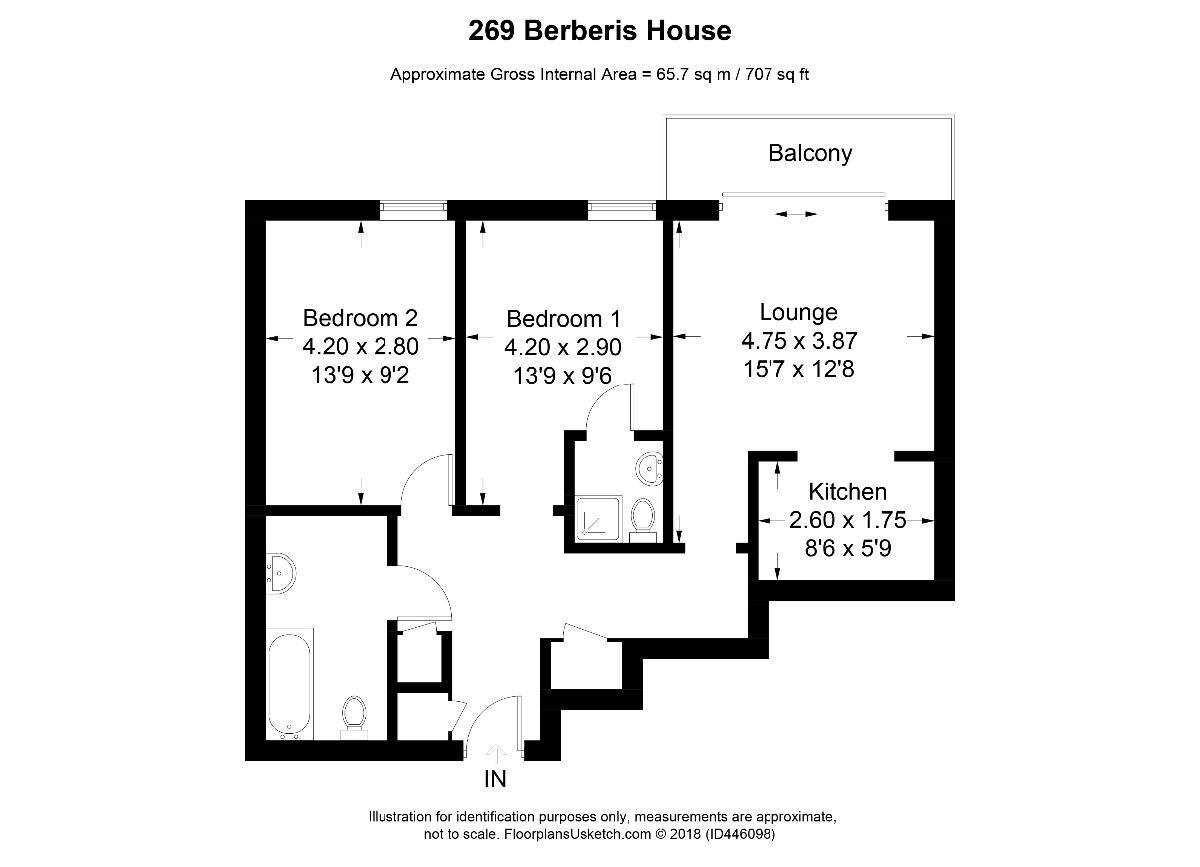
I'm attempting to use OpenCV for text detection of Canadian apartment floor plans for the purpose of building text boxes which can be run through an OCR. The current code works quite well for some but less well for other images
img = cv2.imread("Image.jpg")
mask = np.zeros(img.shape, dtype=np.uint8)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, threshold = cv2.threshold(gray,150,255,cv2.THRESH_BINARY_INV)
_, contours, hierarchy = cv2.findContours(threshold,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
ROI = []
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
if h < 20:
cv2.drawContours(mask, [cnt], 0, (255,255,255), 1)
kernel = np.ones((7,7),np.uint8)
dilation = cv2.dilate(mask,kernel,iterations = 1)
gray_d = cv2.cvtColor(dilation, cv2.COLOR_BGR2GRAY)
_, threshold_d = cv2.threshold(gray_d,150,255,cv2.THRESH_BINARY)
_, contours_d, hierarchy = cv2.findContours(threshold_d,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
for cnt in contours_d:
x,y,w,h = cv2.boundingRect(cnt)
if w > 35:
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
roi_c = img[y:y+h, x:x+w]
ROI.append(roi_c)
config = ("-l eng --oem 3 --psm 6")
for R in ROI:
text = pytesseract.image_to_string(R, config=config)
print(text)
The output for two images is:
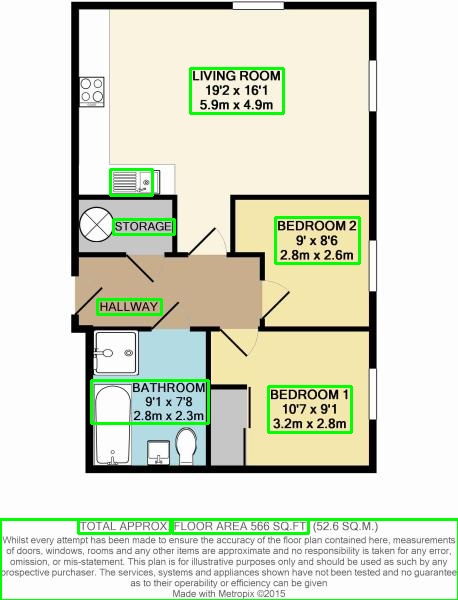{kind=link}
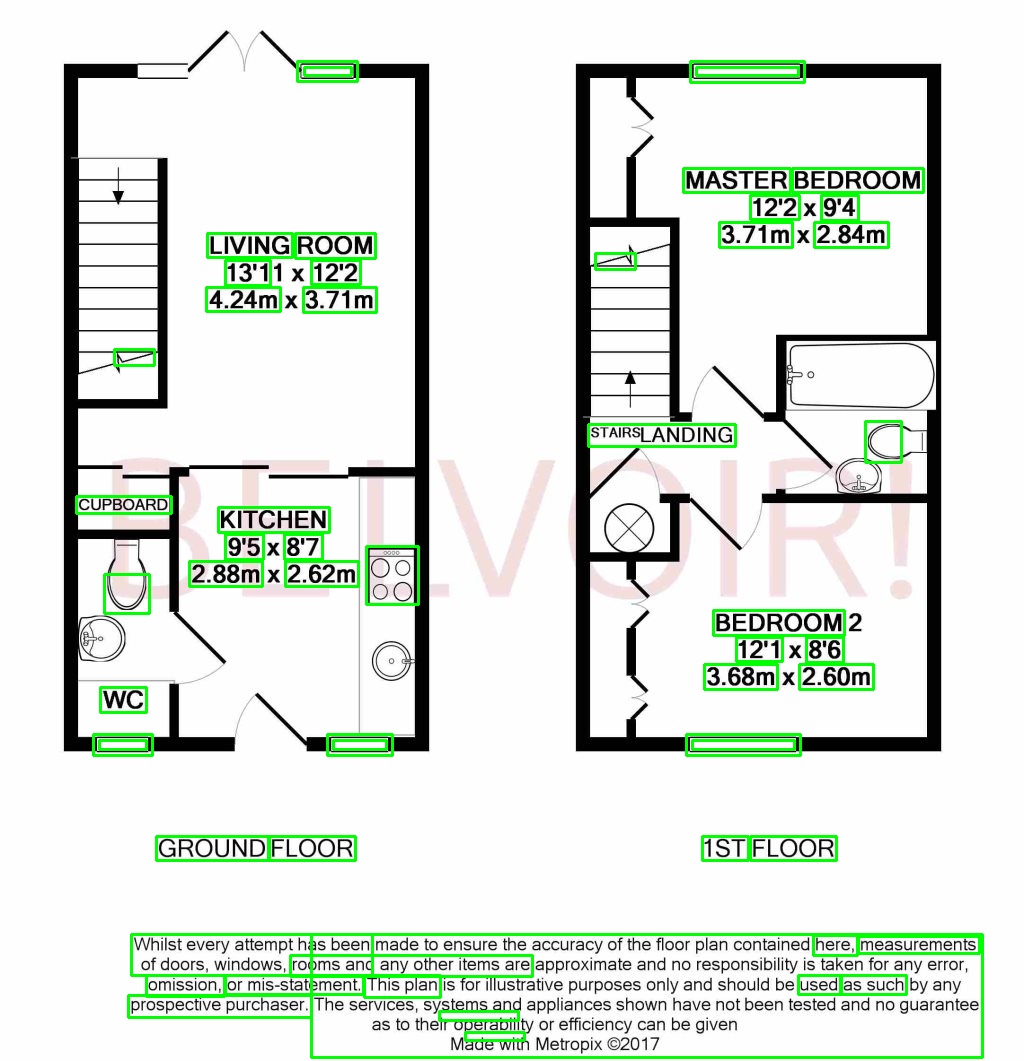{kind=link}
The main questions are: 1) Is there anything in OpenCV 4 that may be of use to improving the accuracy of the text detector? For example, there is TextDetectorCNN, but I have minimal experience in it and there is no example of its implmentation in Python. 2) Is there any other OpenCV techniques that may be useful? Is there a way to combine boxes that are close together. For example in the second image, combining the room name and its dimensions into one box.
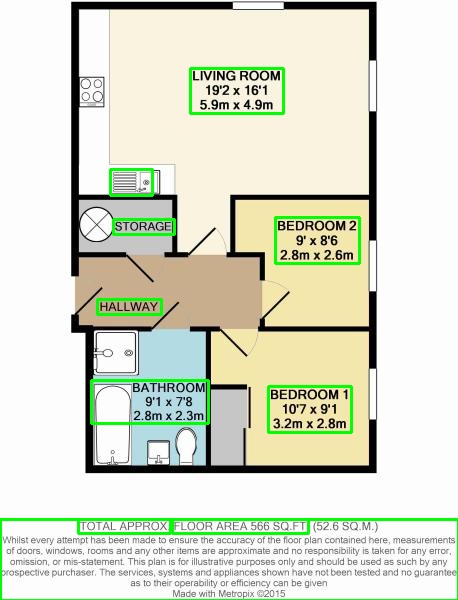{kind=link}
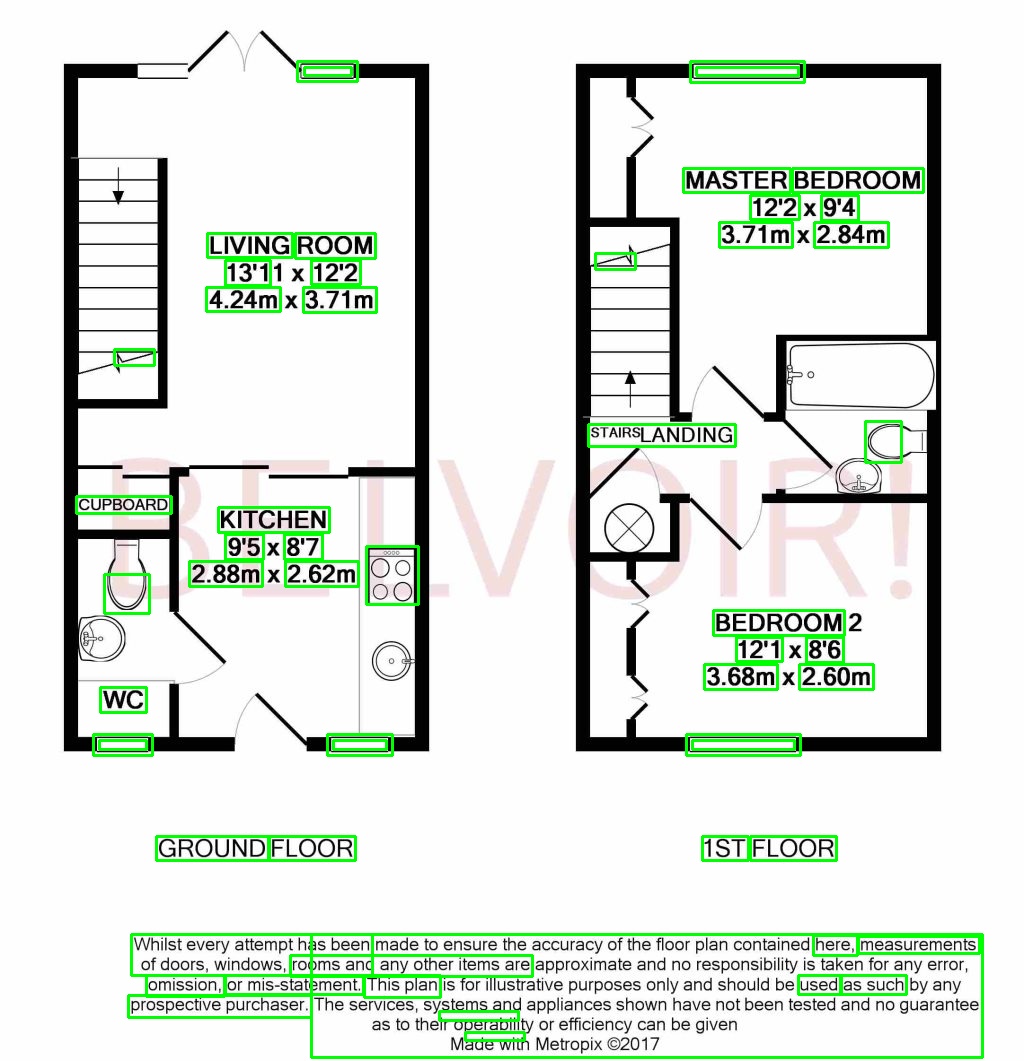{kind=link}
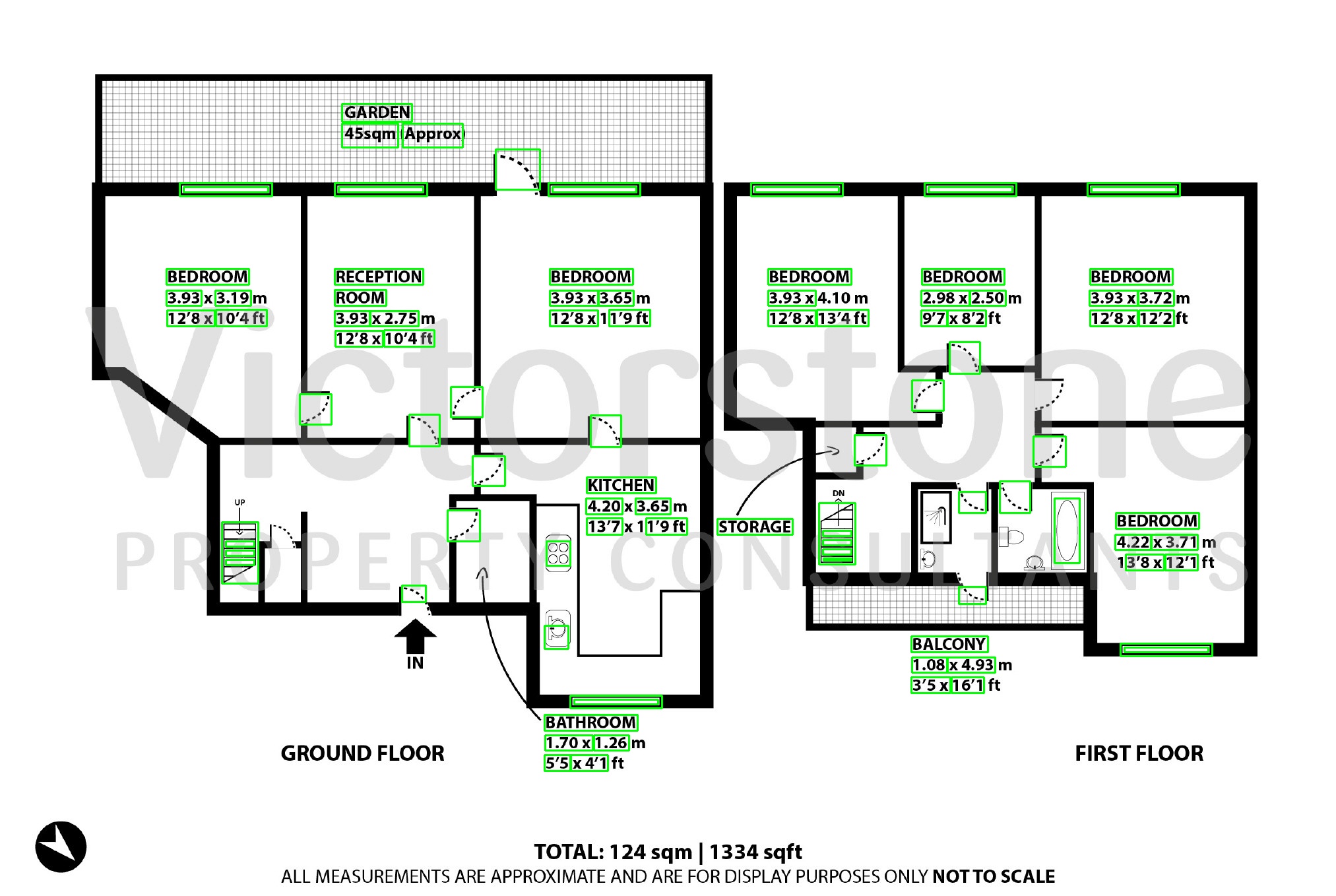{kind=link}
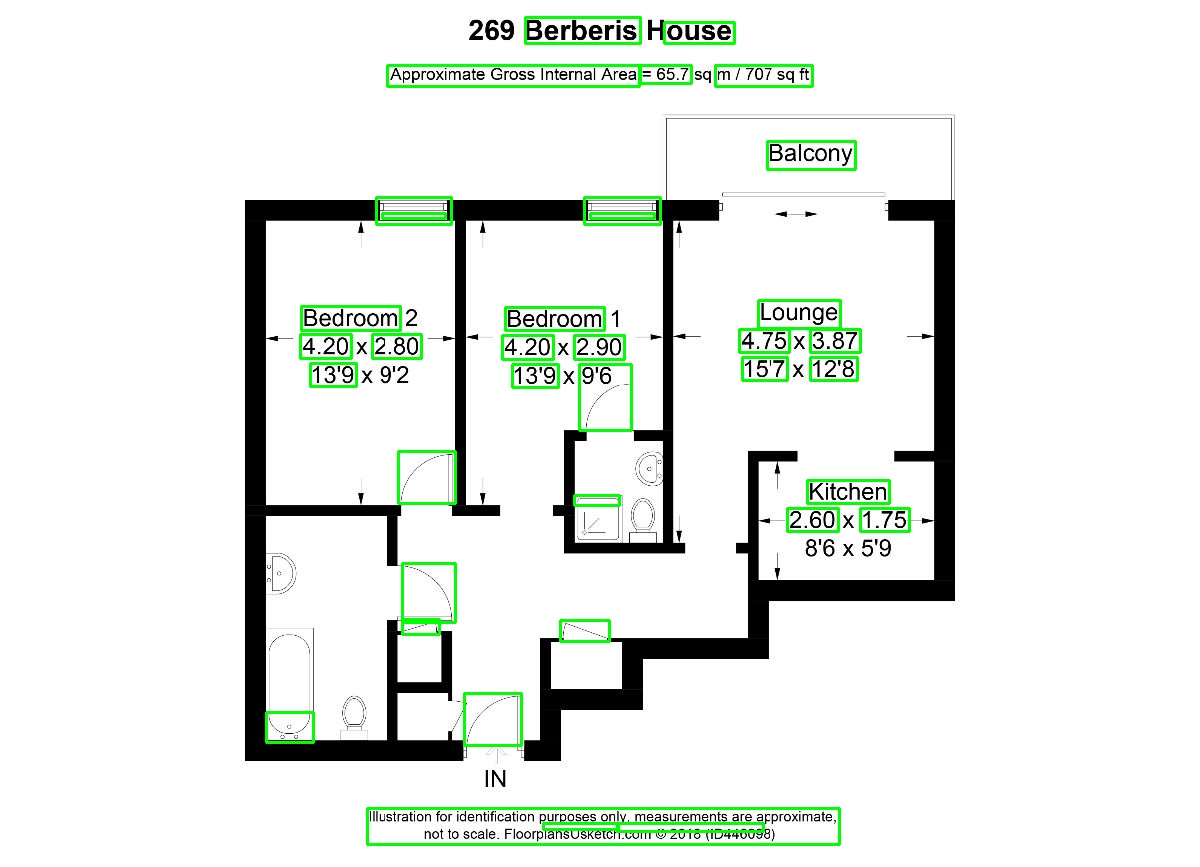{kind=link}
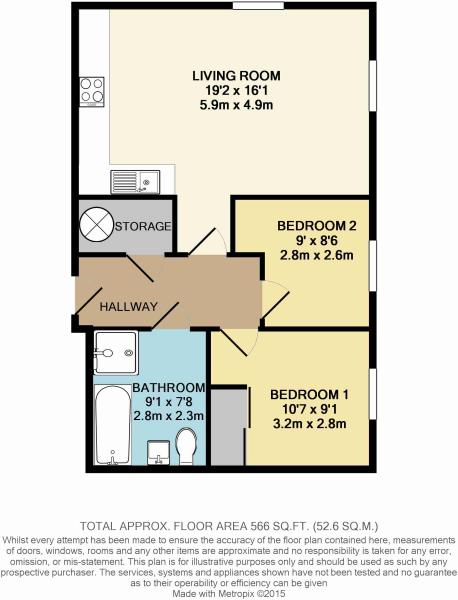{kind=link}
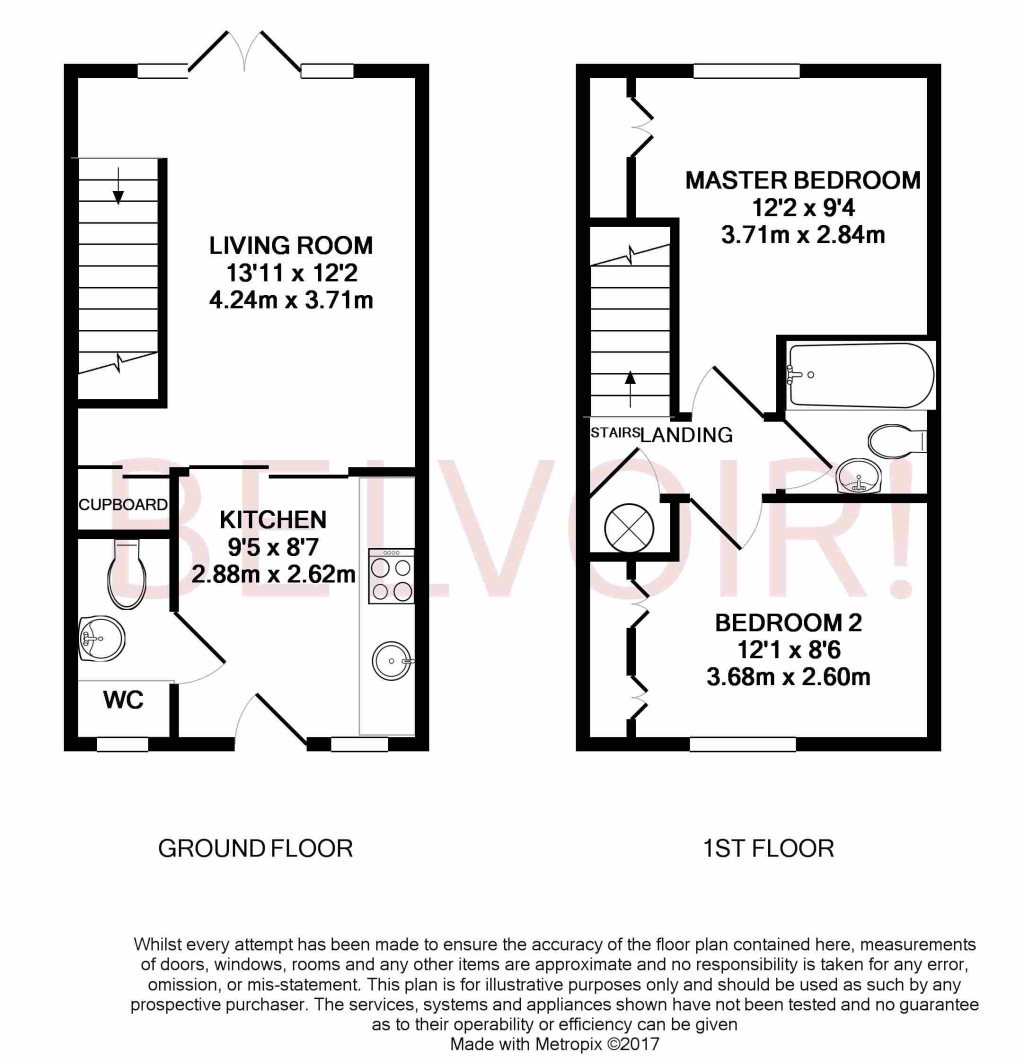{kind=link}
{kind=link}
{kind=link}