How to do OCR training for the following problem ???
This is a sample program to train with sample dataset given by opencv itself.
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the data, converters convert the letter to a number
data= np.loadtxt('letter-recognition.data', dtype= 'float32', delimiter = ',',
converters= {0: lambda ch: ord(ch)-ord('A')})
# split the data to two, 10000 each for train and test
train, test = np.vsplit(data,2)
# split trainData and testData to features and responses
responses, trainData = np.hsplit(train,[1])
labels, testData = np.hsplit(test,[1])
# Initiate the kNN, classify, measure accuracy.
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE,responses)
ret, result, neighbours, dist = knn.findNearest(testData, k=5)
correct = np.count_nonzero(result == labels)
accuracy = correct*100.0/10000
print accuracy
This program reads four pics and converts to text using tesseract.But its highly in accurate .This is a scoreboard of a game and I have over 2000 screenshots of it with me .I am trying to build a application that will read the scoreboard images and build a textual output.
import sys
import cv2
import numpy as np
import pytesseract
from PIL import Image
reload(sys)
sys.setdefaultencoding('utf-8')
# Path of working folder on Disk
src_path = "D:/"
def get_string(img_path):
# Read image with opencv
img = cv2.imread(img_path)
# Convert to gray
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply dilation and erosion to remove some noise
kernel = np.ones((1, 1), np.uint8)
img = cv2.dilate(img, kernel, iterations=1)
img = cv2.erode(img, kernel, iterations=1)
# Write image after removed noise
cv2.imwrite(src_path + "removed_noise.png", img)
# Apply threshold to get image with only black and white
#img = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)
# Write the image after apply opencv to do some ...
cv2.imwrite(src_path + "thres.png", img)
print "Worked Till here"
# Recognize text with tesseract for python
result = pytesseract.image_to_string(Image.open(src_path + "thres.png"))
# Remove template file
#os.remove(temp)
return result
#print '--- Start recognize text from image ---'
#print get_string(src_path + "TeamName1.jpg")
#print get_string(src_path + "TeamName2.jpg")
#print get_string(src_path + "TeamScore1.jpg")
#print get_string(src_path + "TeamScore2.jpg")
#print "------ Done -------"
f= open("TeamName1.txt","w")
f.write(get_string(src_path + "TeamName1.jpg"))
f.close()
f= open("TeamName2.txt","w")
f.write(get_string(src_path + "TeamName2.jpg"))
f.close()
f= open("TeamScore1.txt","w")
f.write(get_string(src_path + "TeamScore1.jpg"))
f.close()
f= open("TeamScore2.txt","w")
f.write(get_string(src_path + "TeamScore2.jpg"))
f.close()
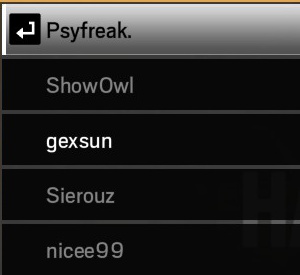

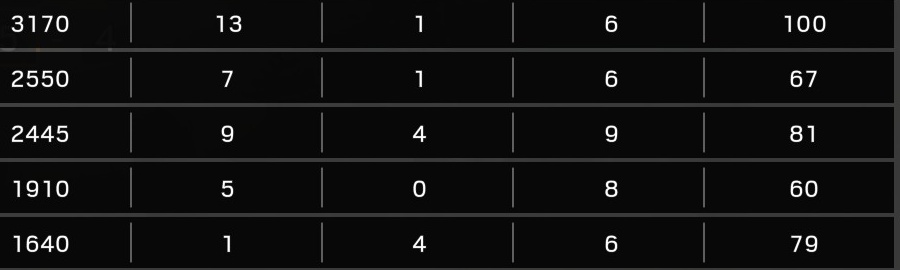

But the outputs of similar pictures are vastly different
Output of first picture of names 2 are missing
g exsu n
Sierouz
niceeQQ
Output of second picture of names 5 out puts are received but has some errors
YEET_Wurmva
Hk_Snekluns
th anh pi
SmittyYO
YEET_Ieckmedeck
Output of first team's scorecard no idea why its like this
222
63
101
100
79
_
2 3 .I 0.0
_
_
_
||||_|
,
_
w 5 8 5n7
xlllrl
_
_
“
07M0 5_5
8 9,8 7.7
9 7N2 1.1
4 4“4 ...
did you save screenshots as jpg?